
JIS X 0201 - JIS X 0201
 JIS X 0201 Pagina codice a 8 bit
| |
| MIME / IANA |
8-bit : JIS_X02017-bit romana : JIS_C6220-1969-ro7-bit Kana : JIS_C6220-1969-jp
|
|---|---|
| Alias | JIS C 6220 8 bit : csHalfWidthKatakana Roman : ISO646-JP , iso-ir-14 Kana : iso-ir-13, x0201-7 |
| Le lingue) | giapponese (supporto di base), inglese |
| Standard | JIS X 0201:1969 |
| Classificazione | ISO 646 , ISO 646 estesa |
| Preceduto da | Codice Wabun , JIS C 0803 |
| seguito da | Maiusc JIS |
| Altre codifiche correlate | Codice Hangul a N byte |
JIS X 0201 , uno standard industriale giapponese sviluppato nel 1969 (poi chiamato JIS C 6220 fino alla riforma della categoria JIS), è stato il primo set di caratteri elettronici giapponese ad essere ampiamente utilizzato. È una codifica a 7 bit o una codifica a 8 bit, sebbene la codifica a 8 bit sia dominante per l'uso moderno. Il nome completo di questo standard è set di caratteri codificati a 7 e 8 bit per lo scambio di informazioni ( 7ビット及び8ビットの情報交換用符号化文字集合).
I primi 96 codici comprendono una variante ISO 646 , per lo più seguendo ASCII con alcune differenze, mentre i secondi 96 codici di caratteri rappresentano i segni fonetici katakana giapponesi . Poiché la codifica non fornisce alcun modo per esprimere hiragana o kanji , è solo in grado di esprimere un giapponese scritto semplificato. Tuttavia, è possibile esprimere, almeno foneticamente, l'intera gamma di suoni nella lingua. Negli anni '80, questo era accettabile per i media come terminali di computer in modalità testo, telegrammi, ricevute o altri dati gestiti elettronicamente.
JIS X 0201 è stato soppiantato da codifiche successive come Shift JIS (che combina questo standard e JIS X 0208 ) e successivamente Unicode .
Storia
Il Comite Consultatif International Telephonique et Telegraphique (CCITT) ha introdotto il codice International Telegraph Alphabet No.2 (ITA2) come standard internazionale, che era la codifica latina a 5 bit. La maggior parte dei paesi ha i propri standard nazionali basati su questo. In Giappone, l'Agenzia per la scienza e la tecnologia industriale (AIST) lo ha standardizzato come codici a 6 bit di caratteri di JIS C 0803-1961 ( layout di tastiera e codici per telescriventi ), che si combinavano con i caratteri katakana. Tuttavia, non corrispondeva ai requisiti del settore perché la mappa dei caratteri era piccola e il layout del codice non era pratico. L'AIST ha considerato una pratica codifica dei caratteri per sostituire vari codici utilizzati in Giappone.
Nel 1963, ISO ha introdotto una bozza di ISO R 646 ( set di caratteri codificati a 6 e 7 bit per lo scambio di elaborazione delle informazioni ). L'AIST ha affidato all'Information Processing Society of Japan (IPSJ) la congiunzione della ISO R 646 e della mappatura katakana . L'IPSJ ha formato il comitato per la standardizzazione del codice. Il comitato non ha adottato la forma a 6 bit della bozza dell'ISO perché il set katakana non poteva adattarsi alla sua mappa dei caratteri. La prima bozza di JIS mappava piccoli caratteri katakana accanto a ciascuno dei loro normali caratteri katakana. Era considerato conveniente per l'ordinamento per ordine di Gojūon . Alcuni membri del comitato hanno criticato che avrebbe complicato la meccanica delle tastiere che gestivano solo i normali caratteri katakana. La bozza successiva ha mappato piccoli caratteri katakana nelle posizioni 0xA7-0xAF. Nel 1966, la quarta bozza dell'ISO specificava il simbolo della valuta nazionale a 0x24 e il comitato JIS progettò di mappare il segno dello yen . La prima edizione della ISO 646 è stata pubblicata nel 1967. Specificava il simbolo del dollaro ASCII 0x24 come carattere invariante, quindi il comitato JIS decise di sostituire la barra rovesciata 0x5c dell'ASCII (uno dei caratteri varianti) con il segno dello yen. Tuttavia, la CCITT ha introdotto l'alfabeto internazionale n. 5 (IA5) nel 1968, che affermava che non era richiesto il simbolo del dollaro e che poteva essere sostituito con il segno della valuta internazionale (¤). La ISO 646 è stata rivista nel 1973 per conformarsi alla IA5.
JIS C 6220 ( Codici per lo scambio di informazioni , 情報交換用符号) è stato pubblicato nel 1969. Il suo numero è stato cambiato in JIS X 0201 a causa della riforma della categoria JIS nel 1987 e il nome è stato cambiato in codificato a 7 bit e 8 bit set di caratteri per lo scambio di informazioni (7ビット及び8ビットの情報交換用符号化文字集合) nell'edizione del 1990.
Il set di caratteri di JIS X 0201 era stato ampiamente utilizzato in Giappone. Il Nationwide Banking Data Communication System (全国銀行データ通信システム), il più grande sistema di trasferimento di fondi in Giappone, è stato istituito nel 1973. I messaggi di transazione tra le banche utilizzavano un sottoinsieme di JIS X 0201. Il sistema era stato utilizzato fino al 2018 ed era sostituito dallo ZEDI (The Nationwide Banking Electronic Data Interchange System, 全銀EDIシステム) che poteva gestire i caratteri hiragana e kanji. Nel 1978, il set di caratteri a 2 byte JIS C 6226 ( JIS X 0208 ) è stato sviluppato per esprimere i caratteri hiragana e kanji. Include i caratteri katakana, ma i loro codici e layout sono diversi da JIS X 0201. I produttori di computer hanno sviluppato le proprie estensioni di JIS X 0208 per mantenere la compatibilità con JIS X 0201. Nel 1982, lo schema di codifica Microsoft Kanji ( Codepage 932 di MS-DOS ) e SJC26 di Digital Research (per il giapponese CP/M-86 ) sono stati sviluppati per combinare la codifica a byte singolo JIS X 0201 e la codifica a byte doppio JIS X 0208 senza shift out e shift in caratteri. Si chiamavano Shift JIS , che divenne lo standard industriale per i personal computer.
Dettagli di implementazione


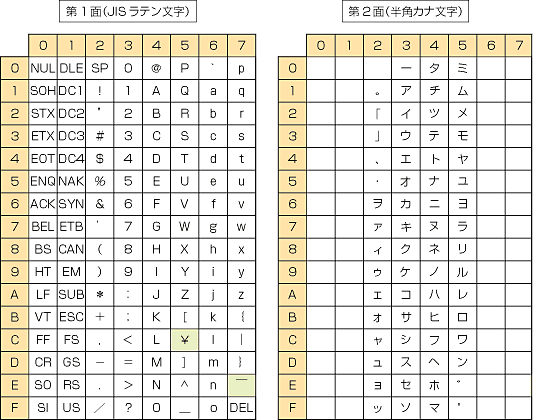
La prima metà (set romano) di JIS X 0201 costituisce una variante giapponese della ISO 646 , pari ad ASCII con barra rovesciata (\) e tilde (~) sostituite da yen (¥) e overline (‾), mentre la seconda metà (Kana set) consiste principalmente di katakana . I caratteri di controllo sono specificati in JIS X 0211 .
Nel formato a 7 bit, il carattere di controllo shift out (0x0E) passa al set Kana e shift in (0x0F) passa al set romano. Nel formato a 8 bit, riportato nella tabella sottostante, i byte con il bit più significativo impostato (es. 0x80–0xFF) vengono utilizzati per l'insieme Kana e i byte con esso non impostato (es. 0x00–0x7F) vengono utilizzati in caso contrario.
I nomi usati specificamente per il set romano a 7 bit includono "JISCII", "JIS Roman", "ISO646-JP", "JIS C6220-1969-ro", "Japanese-Roman", "Japan 7-Bit Latin" e "ISO-IR-14", mentre i nomi utilizzati specificamente per il set Kana a 7 bit includono "ISO-IR-13", "JIS C6220-1969-jp" e "x0201-7".
La sostituzione del simbolo yen per la barra rovesciata può rendere i percorsi su computer basati su DOS e Windows con supporto giapponese visualizzati in modo strano, come "C:¥Programmi¥", ad esempio. Un altro problema simile sono i caratteri di controllo del linguaggio di programmazione C dei letterali stringa , come printf("Hello, world.¥n");.
Layout della tabella codici
La tabella seguente è il set di caratteri codificati a 8 bit originale di JIS X 0201 (con il set di kana indicato da byte con il set di bit alto).
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 |
Codici C0 0000-001F |
|||||||||||||||
| 1_ 16 |
||||||||||||||||
| 2_ 32 |
SP 0020 |
! 0021 |
" 0022 |
# 0023 |
$ 0024 |
% 0025 |
& 0026 |
' 0027 |
( 0028 |
) 0029 |
* 002A |
+ 002B |
, 002C |
- 002D |
. 002E |
/ 002F |
| 3_ 48 |
0 0030 |
1 0031 |
2 0032 |
3 0033 |
4 0034 |
5 0035 |
6 0036 |
7 0037 |
8 0038 |
9 0039 |
: 003A |
; 003B |
< 003C |
= 003D |
> 003E |
? 003F |
| 4_ 64 |
@ 0040 |
A 0041 |
B 0042 |
C 0043 |
D 0044 |
E 0045 |
F 0046 |
G 0047 |
H 0048 |
io 0049 |
J 004A |
K 004B |
L 004C |
M 004D |
N 004E |
O 004F |
| 5_ 80 |
P 0050 |
Q 0051 |
R 0052 |
S 0053 |
T 0054 |
U 0055 |
V 0056 |
W 0057 |
X 0058 |
Y 0059 |
Z 005A |
[ 005B |
¥ 00A5 |
] 005D |
^ 005E |
_ 005F |
| 6_ 96 |
` 0060 |
uno 0061 |
b 0062 |
c 0063 |
d 0064 |
e 0065 |
f 0066 |
g 0067 |
ore 0068 |
io 0069 |
j 006A |
k 006B |
l 006C |
m 006D |
n 006E |
o 006F |
| 7_ 112 |
p 0070 |
q 0071 |
r 0072 |
s 0073 |
t 0074 |
tu 0075 |
v 0076 |
w 0077 |
x 0078 |
e 0079 |
z 007A |
{ 007B |
| 007C |
} 007D |
~ 203E |
DEL 007F |
| 8_ 128 |
Codici C1 o Blocco vuoto 0080-009F |
|||||||||||||||
| 9_ 144 |
||||||||||||||||
| A_ 160 |
. FF61 |
「 FF62 |
」 FF63 |
, FF64 |
· FF65 |
ヲ FF66 |
ァ FF67 |
ィ FF68 |
ゥ FF69 |
ェ FF6A |
ォ FF6B |
ャ FF6C |
ュ FF6D |
ョ FF6E |
ッ FF6F |
|
| B_ 176 |
ー FF70 |
ア FF71 |
イ FF72 |
ウ FF73 |
エ FF74 |
オ FF75 |
カ FF76 |
キ FF77 |
ク FF78 |
ケ FF79 |
コ FF7A |
サ FF7B |
シ FF7C |
ス FF7D |
セ FF7E |
ソ FF7F |
| C_ 192 |
タ FF80 |
チ FF81 |
ツ FF82 |
テ Ff83 |
ト FF84 |
ナ FF85 |
ニ FF86 |
ヌ FF87 |
ネ FF88 |
ノ FF89 |
ハ FF8A |
ヒ FF8B |
フ FF8C |
ヘ FF8D |
ホ FF8E |
マ FF8F |
| D_ 208 |
ミ FF90 |
ム FF91 |
メ FF92 |
モ FF93 |
ヤ FF94 |
ユ FF95 |
ヨ FF96 |
ラ FF97 |
リ FF98 |
ル FF99 |
レ FF9A |
ロ FF9B |
ワ FF9C |
ン FF9D |
゙ FF9E |
゚ FF9F |
| E_ 224 |
||||||||||||||||
| F_ 240 |
||||||||||||||||
Lettera Numero Punteggiatura Simbolo Altro Non definito
Come parte di Shift JIS
Di seguito è riportata la mappatura utilizzata per JIS X 0201 come parte di Shift JIS , ovvero che mostra la forma a 8 bit di JIS X 0201 e mappando i caratteri Katakana al blocco Halfwidth e Fullwidth Forms (che a sua volta deriva il suo layout kana a mezza larghezza da JIS X 0201).
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 |
||||||||||||||||
| 1_ 16 |
||||||||||||||||
| 2_ 32 |
SP 0020 |
! 0021 |
" 0022 |
# 0023 |
$ 0024 |
% 0025 |
& 0026 |
' 0027 |
( 0028 |
) 0029 |
* 002A |
+ 002B |
, 002C |
- 002D |
. 002E |
/ 002F |
| 3_ 48 |
0 0030 |
1 0031 |
2 0032 |
3 0033 |
4 0034 |
5 0035 |
6 0036 |
7 0037 |
8 0038 |
9 0039 |
: 003A |
; 003B |
< 003C |
= 003D |
> 003E |
? 003F |
| 4_ 64 |
@ 0040 |
A 0041 |
B 0042 |
C 0043 |
D 0044 |
E 0045 |
F 0046 |
G 0047 |
H 0048 |
io 0049 |
J 004A |
K 004B |
L 004C |
M 004D |
N 004E |
O 004F |
| 5_ 80 |
P 0050 |
Q 0051 |
R 0052 |
S 0053 |
T 0054 |
U 0055 |
V 0056 |
W 0057 |
X 0058 |
Y 0059 |
Z 005A |
[ 005B |
¥ 00A5 |
] 005D |
^ 005E |
_ 005F |
| 6_ 96 |
` 0060 |
uno 0061 |
b 0062 |
c 0063 |
d 0064 |
e 0065 |
f 0066 |
g 0067 |
ore 0068 |
io 0069 |
j 006A |
k 006B |
l 006C |
m 006D |
n 006E |
o 006F |
| 7_ 112 |
p 0070 |
q 0071 |
r 0072 |
s 0073 |
t 0074 |
tu 0075 |
v 0076 |
w 0077 |
x 0078 |
e 0079 |
z 007A |
{ 007B |
| 007C |
} 007D |
~ 203E |
|
| 8_ 128 |
||||||||||||||||
| 9_ 144 |
||||||||||||||||
| A_ 160 |
. FF61 |
「 FF62 |
」 FF63 |
, FF64 |
· FF65 |
ヲ FF66 |
ァ FF67 |
ィ FF68 |
ゥ FF69 |
ェ FF6A |
ォ FF6B |
ャ FF6C |
ュ FF6D |
ョ FF6E |
ッ FF6F |
|
| B_ 176 |
ー FF70 |
ア FF71 |
イ FF72 |
ウ FF73 |
エ FF74 |
オ FF75 |
カ FF76 |
キ FF77 |
ク FF78 |
ケ FF79 |
コ FF7A |
サ FF7B |
シ FF7C |
ス FF7D |
セ FF7E |
ソ FF7F |
| C_ 192 |
タ FF80 |
チ FF81 |
ツ FF82 |
テ Ff83 |
ト FF84 |
ナ FF85 |
ニ FF86 |
ヌ FF87 |
ネ FF88 |
ノ FF89 |
ハ FF8A |
ヒ FF8B |
フ FF8C |
ヘ FF8D |
ホ FF8E |
マ FF8F |
| D_ 208 |
ミ FF90 |
ム FF91 |
メ FF92 |
モ FF93 |
ヤ FF94 |
ユ FF95 |
ヨ FF96 |
ラ FF97 |
リ FF98 |
ル FF99 |
レ FF9A |
ロ FF9B |
ワ FF9C |
ン FF9D |
゙ FF9E |
゚ FF9F |
| E_ 224 |
||||||||||||||||
| F_ 240 |
Le celle rosse indicano i primi byte dei caratteri Shift JIS a doppio byte.
Mappatura alternativa di katakana
Il profilo ISO-2022-JP di base non consente il set Kana di JIS X 0201, solo il set Roman e JIS X 0208 (sebbene lo stesso ISO 2022 / JIS X 0202 lo permetta). Di conseguenza, quando si converte JIS X 0201 katakana (o Unicode half-width kana , che utilizzano lo stesso layout) in ISO-2022-JP, viene spesso utilizzata la seguente mappatura o trasformazione. Ciò consente di convertire il kana in JIS X 0208.
In teoria, questa mappatura è ugualmente corretta, poiché JIS X 0201 stesso non specifica la larghezza di visualizzazione, sebbene in pratica (e specialmente in ambienti duospaced ) JIS X 0201 sia utilizzato per katakana a metà larghezza.
Per facilitare il confronto con il grafico sopra, la mappatura è mostrata di seguito sulla codifica katakana JIS X 0201 e con il set di bit alto.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UN_ |
. 3002 |
「 300C |
」 300D |
, 3001 |
· 30FB |
ヲ 30F2 |
ァ 30A1 |
ィ 30A3 |
ゥ 30A5 |
ェ 30A7 |
ォ 30A9 |
ャ 30E3 |
ュ 30E5 |
ョ 30E7 |
ッ 30C3 |
|
| B_ |
ー 30FC |
ア 30A2 |
イ 30A4 |
ウ 30A6 |
エ 30A8 |
オ 30AA |
カ 30AB |
キ 30AD |
ク 30AF |
ケ 30B1 |
コ 30B3 |
サ 30B5 |
シ 30B7 |
ス 30B9 |
セ 30BB |
ソ 30BD |
| C_ |
タ 30BF |
チ 30C1 |
ツ 30C4 |
テ 30C6 |
ト 30C8 |
ナ 30ca |
ニ 30CB |
ヌ 30CC |
ネ 30CD |
ノ 30CE |
ハ 30CF |
ヒ 30D2 |
フ 30D5 |
ヘ 30D8 |
ホ 30DB |
マ 30DE |
| D_ |
ミ 30df |
ム 30E0 |
メ 30E1 |
モ 30E2 |
ヤ 30E4 |
ユ 30E6 |
ヨ 30E8 |
ラ 30E9 |
リ 30EA |
ル 30EB |
レ 30EC |
ロ 30ED |
ワ 30EF |
ン 30F3 |
゛ 309B |
゜ 309C |
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F |
Varianti ed estensioni
Maiusc JIS
Le implementazioni di IBM
La code page 897 èl'implementazione IBM della forma a 8 bit di JIS X 0201. Include diversi caratteri grafici aggiuntivi nell'area dei caratteri di controllo C0 e i punti di codice in questione possono essere utilizzati come caratteri di controllo o caratteri grafici a seconda del contesto, concettualmente simile a OEM-US , ma con caratteri grafici diversi. Le righe C0 sono mostrate di seguito.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0_ 0 |
NUL 0000 |
╔ 2554 |
╗ 2557 |
╚ 255A |
╝ 255D |
║ 2551 |
═ 2550 |
↓ FFEC |
BS 0008 |
○ FFEE |
LF 000A |
〿 303F |
FF 000C |
CR 000D |
■ FFED |
☼ 263C |
| 1_ 16 |
╬ 256C |
DC1 0011 |
↕ 2195 |
DC3 0013 |
▓ 2593 |
╩ 2569 |
╦ 2566 |
╣ 2563 |
PU 0018 |
╠ 2560 |
░ / FS 2591 / 001C |
↵ 21B5 |
↑ / DEL FFEA / 007F |
│ FFE8 |
→ FFEB |
← FFE9 |
IBM implementa anche il set romano a 7 bit di JIS X 0201 come Code page 895 e il set Kana a 7 bit come Code page 896 per l'uso come set di codici ISO 2022 o EUC-JP . La code page 896, oltre alle assegnazioni JIS X 0201 standard, definisce cinque assegnazioni aggiuntive, mostrate di seguito. Sebbene l'uso di questi caratteri estesi non sia consentito dal CCSID 896 associato , sono consentiti dal CCSID 4992 alternativo.
| _0 | _1 | _2 | _3 | _4 | _5 | _6 | _7 | _8 | _9 | _UN | _B | _C | _D | _E | _F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 6_ 96 |
¢ 00A2 |
£ 00A3 |
¬ 00AC |
\ 005C |
~ 007E |
La Code page 1041 di IBM è una versione estesa della Code page 897, che codifica questi cinque caratteri estesi IBM in posizioni alternative compatibili con Shift JIS (rispettivamente 0x80, 0xA0, 0xFD, 0xFE e 0xFF).
La Code page 903 di IBM è codificata per essere utilizzata come componente a byte singolo di alcune codifiche di caratteri cinesi semplificate . Nonostante ciò, segue ISO 646-JP / la metà romana di JIS X 0201, in quanto sostituisce la barra rovesciata ASCII 0x5C (piuttosto che il simbolo del dollaro ASCII 0x24 come in GB 1988 / ISO 646-CN ) con il segno yen/yuan . Utilizza anche la stessa grafica sostitutiva C0 della code page 897. È strettamente correlato aCode page 904 , che è codificata per essere utilizzata come componente a byte singolo di alcune codifiche di caratteri cinesi tradizionali e utilizza la stessa grafica sostitutiva C0, ma segue ASCII .
Altri

NEC PC-8001 (1979) set di caratteri come reso nel font 8×8 pixel

Variante Hitachi utilizzata sull'HD44780 .


{kind=link}